Active Reinforcement Learning Strategies for Offline Policy Improvement
(Work focuses on developing active stratergies on collecting data from environment to improve the policy in offline Reinforcemnet learning)
Explore Our ResearchLearning agents that excel at sequential decision-making tasks must continuously resolve the problem of exploration and exploitation for optimal learning. However, such interactions with the environment online might be prohibitively expensive and may involve some constraints, such as a limited budget for agent-environment interactions and restricted exploration in certain regions of the state space. Examples include selecting candidates for medical trials and training agents in complex navigation environments. This problem necessitates the study of active reinforcement learning strategies that collect minimal additional experience trajectories by reusing existing offline data previously collected by some unknown behavior policy. In this work, we propose an active reinforcement learning method capable of collecting trajectories that can augment existing offline data. With extensive experimentation, we demonstrate that our proposed method reduces additional online interaction with the environment by up to 75% over competitive baselines across various continuous control environments such as Gym-MuJoCo locomotion environments as well as Maze2d, AntMaze, CARLA and IsaacSimGo1. To the best of our knowledge, this is the first work that addresses the active learning problem in the context of sequential decision-making and reinforcement learning.
Introduction
Reinforcement Learning (RL) is a framework for sequential decision-making where agents learn optimal behaviors by interacting with an environment to maximize cumulative rewards. Traditional RL relies on online exploration, which can be impractical in real-world applications like autonomous navigation or clinical trials. Offline RL addresses this by enabling agents to learn from pre-collected datasets without online interaction. However, a critical challenge arises: how to enhance agent performance when limited online exploration is permitted alongside offline data? . This problem mirrors Active Learning in supervised learning, where agents strategically select the most informative unlabeled data to label, optimizing learning under budget constraints. In RL, the challenge is more complex—agents must decide where, how, and how long to explore within an environment, balancing between collecting lengthy trajectories (for deep exploration) and shorter, diverse trajectories (to cover under-sampled regions). For instance, an autonomous vehicle might prioritize exploring unfamiliar areas over redundant data-rich zones. This work develops algorithms to optimize such active exploration, leveraging offline datasets to guide efficient, budget-limited online interactions and improve learning outcomes.
Background
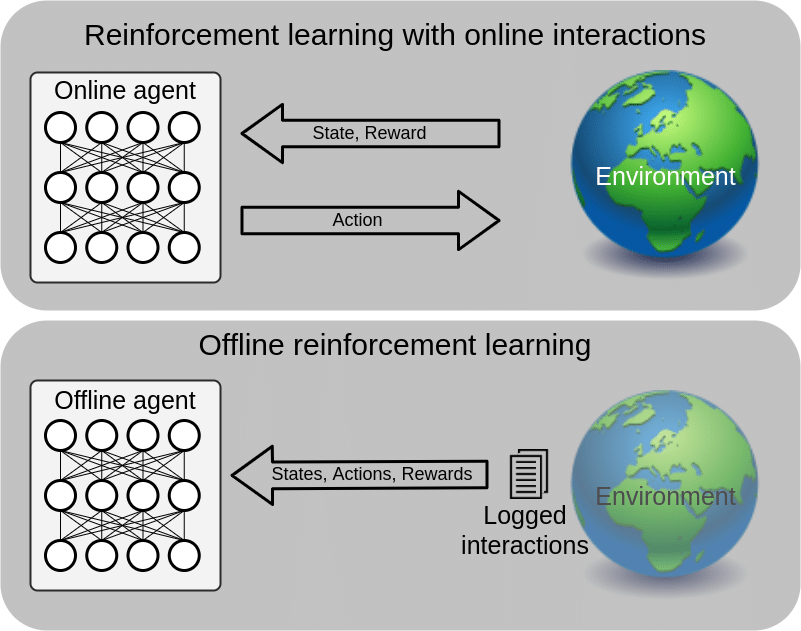
Reinforcement Learning (RL) is a paradigm for sequential decision-making where agents learn optimal behaviors by interacting with an environment to maximize cumulative rewards. Traditional RL relies on online exploration, where agents iteratively collect data through trial-and-error. While effective in simulated settings, this approach becomes impractical in real-world applications—such as clinical trials, autonomous navigation, or robotics—where interactions are costly, risky, or constrained by safety protocols.
To address these limitations, offline RL has emerged as a promising alternative. Here, agents learn from a fixed dataset of pre-collected interactions, eliminating the need for risky online exploration. However, offline RL faces a critical challenge: the dataset may lack coverage of critical states or actions, especially if the environment changes between data collection and deployment. For instance, an autonomous vehicle trained on urban driving data might struggle in rural settings absent from the dataset. This limitation necessitates strategic online exploration to complement offline data, but under strict budget constraints.
This problem mirrors Active Learning in supervised learning, where agents select the most informative unlabeled data points to annotate, maximizing model performance with minimal labeling effort. However, in RL, the challenge is more complex. Instead of selecting static data points, agents must decide:
- Where to explore (e.g., under-sampled regions).
- How to explore (e.g., trajectory length).
- When to stop (e.g., avoiding redundant states).
Prior work in RL exploration has focused on uncertainty-driven methods, such as:
- Count-based exploration: Encouraging visits to rarely seen states.
- Intrinsic rewards: Using curiosity or prediction errors to guide exploration.
- Ensemble disagreement: Leveraging model variance to identify uncertain regions.
While these methods excel in pure online RL, they do not account for pre-existing offline datasets. Conversely, offline RL algorithms like CQL (Conservative Q-Learning) and IQL (Implicit Q-Learning) regularize policies to avoid overestimation errors but lack mechanisms for targeted online data collection. Bridging this gap requires a framework that actively guides exploration using uncertainty estimates derived from offline data.
Our work builds on these foundations to address a key question: How can agents efficiently collect new trajectories—within a limited interaction budget—to augment an offline dataset and learn robust policies? We propose that representation-aware uncertainty estimation is critical to identifying under-explored regions while reusing knowledge from offline data. By combining insights from active learning and offline RL, we design a method that strategically allocates exploration resources, ensuring every interaction maximizes learning progress.
- State encoder \( E_s \): Maps states to latent embeddings.
- Action encoder \( E_a \): Maps actions to latent embeddings.
- Clustering: We ensure that similar states are clustered in the latent space.
- Transition Dynamics Modeling: We enforce that the embedding of a state-action pair aligns with the next state’s embedding.
- At each step, we sample multiple actions from the current policy (e.g., TD3+BC or IQL) and select the action leading to the most uncertain state-action pair.
- We employ an \( \epsilon \)-greedy strategy:
- With probability \( \epsilon \), we explore using uncertainty-driven actions.
- Otherwise, we follow the offline policy.
- Reach Phase: We use a goal-conditioned policy (trained offline) to navigate from the default initial state to a high-uncertainty region in the current offline dataset.
- Explore Phase: Once the target region is reached, we switch to our uncertainty-driven exploration policy.
Proposed Method:
To address the challenge of enhancing an agent’s performance using limited online interactions alongside offline data, we propose a representation-aware uncertainty-based active exploration strategy. Our method efficiently guides the agent to collect high-value trajectories in under-explored regions of the environment, minimizing redundant data collection.
1. Representation-Aware Uncertainty Estimation
The core idea is to quantify epistemic uncertainty (model uncertainty due to lack of data) in the state-action space using an ensemble of representation models.
Model Architecture
We design two encoders:
State-action pairs are encoded as:
\[ E(s,a) = E_s(s) + E_a(a) \]
Training Objectives
Uncertainty Calculation
For a given state or state-action pair, we compute the disagreement among the ensemble’s predictions.
We use the maximum squared difference between embeddings across ensemble members as our uncertainty metric.
2. Active Exploration Policy
Using the uncertainty estimates, we strategically determine where to start exploring and how to collect trajectories.
Initial State Selection
We sample candidate initial states:
\[ C \sim {\rho} \]
We prioritize states with the highest uncertainty, focusing on regions that are poorly covered by the offline dataset.
Trajectory Collection
Trajectory Termination
We stop collecting data in regions where uncertainty falls below a threshold to avoid redundancy.
3. Handling Restricted Initial States
In environments where initial states cannot be freely chosen , we employ a two-stage policy:

Our Contributions
Our contributions in this work are as follows:
- We proposed a representation-aware epistemic uncertainty-based method for determining regions of the state space where the agent should collect additional trajectories.
- We proposed an uncertainty-based exploration policy for online trajectory collection that re-uses the representation models.
- Through extensive experimentation, we empirically demonstrated that our approaches can be widely applicable across a range of continuous control environments. Our active trajectory collection method reduces the need for online interactions by up to 75% when compared to existing fine-tuning approaches.
For more details and experiments, Please refer to our paper.
Publication
Active Reinforcement Learning Strategies for Offline Policy Improvement
Ambedkar Dukkipati, Ranga Shaarad Ayyagari, Bodhisattwa Dasgupta,
Parag Dutta, Prabhas Reddy Onteru
The Association for the Advancement of Artificial Intelligence, AAAI 2025
article{@ambedkar2024active
title = {Active Reinforcement Learning Strategies for Offline Policy Improvement},
author = { Ambedkar Dukkipati, Ranga Shaarad Ayyagari, Bodhisattwa Dasgupta,
Parag Dutta, Prabhas Reddy Onteru},
journal = {https://arxiv.org/pdf/2412.13106}
year = {2024}
}
Code
Python implementation together with documentation is available in the GitHub repository.
Authors
- Ambedkar Dukkipati
- Ranga Shaarad Ayyagari
- Bodhisattwa Dasgupta
- Parag Dutta
- Prabhas Reddy Onteru